Dynamic TOC - without initial/previous declaration
-
It not works very well. I mixed the stuff for testing reasons in my test environment in a non linear way.

I really hate to bug you guys, but I find this topic kind of exciting. I would like to get the TOC somehow dynamic. The most suitable way is to read the header directly from DOM, preferably without additional function calls in the html source code. Can i call the
pdfAddPageItemfunction directly via script from my template? Or can deal with the rendered dom in the script section (under the html sourcecode)?So, I want to parse the finished DOM outside the template and pass the found elements to the function
pdfAddPageItempurely script based (not via handlebars). But somehow I can't get to the html source of the finished DOM.
The HMTL DOM is correct. The remixed order in the DOM looks like this:
1. Heading (main) 1.1. Heading (main) 3. Heading (child) 3.1. Heading (child) 3.2. Heading (child) 4. Heading (child-child) 4.1. Heading (child-child) 5. Heading (child-child) 5.1. Heading (child-child) 5.1.1. Heading (child-child) 5.2. Heading (child-child) 1.1.1. Heading (main) 1.2. Heading (main) 1.2.1. Heading (main) 2. Heading (main) 2.1. Heading (main) 2.2. Heading (main) 2.3. Heading (main) 3. Heading (child) 3.1. Heading (child) 3.2. Heading (child) 4. Heading (child-child) 4.1. Heading (child-child) 5. Heading (child-child) 5.1. Heading (child-child) 5.1.1. Heading (child-child) 5.2. Heading (child-child)With a little hassle I get the pdf TOC mapped with the function
pdfAddPageItemand my little helper functionpdfAddTocItem.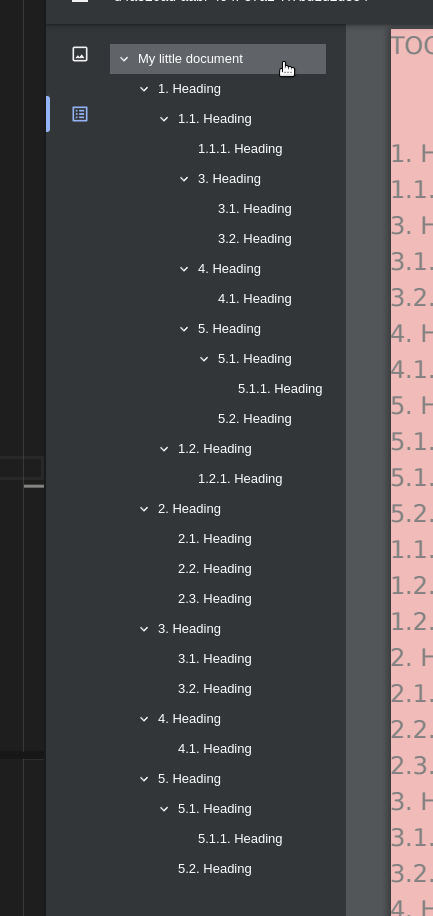
Yes ok that looks a bit weird:
"laterToc": [ { "title": "1. Heading", "parent": "root", "id": "h-1" }, { "title": "1.1. Heading", "parent": "h-1", "id": "h-1-1" }, { "title": "1.1.1. Heading", "parent": "h-1-1", "id": "h-1-1-1" }, { "title": "1.2. Heading", "parent": "h-1", "id": "h-1-2" }, { "title": "1.2.1. Heading", "parent": "h-1-2", "id": "h-1-2-1" }, { "title": "2. Heading", "parent": "root", "id": "h-2" }, { "title": "2.1. Heading", "parent": "h-2", "id": "h-2-1" }, { "title": "2.2. Heading", "parent": "h-2", "id": "h-2-2" }, { "title": "2.3. Heading", "parent": "h-2", "id": "h-2-3" }, { "title": "3. Heading", "parent": "h-1-1", "id": "noh-3" }, { "title": "3.1. Heading", "parent": "noh-3", "id": "nonoh-3" }, { "title": "3.2. Heading", "parent": "noh-3", "id": "noh-3-2" }, { "title": "3. Heading", "parent": "root", "id": "yesh-3" }, { "title": "3.1. Heading", "parent": "yesh-3", "id": "yesyesh-3" }, { "title": "3.2. Heading", "parent": "yesh-3", "id": "yesh-3-2" }, { "title": "4. Heading", "parent": "h-1-1", "id": "abcnoh-4" }, { "title": "4.1. Heading", "parent": "abcnoh-4", "id": "abcnoh-4-1" }, { "title": "5. Heading", "parent": "h-1-1", "id": "abcnoh-5" }, { "title": "5.1. Heading", "parent": "abcnoh-5", "id": "abcnoh-5-1" }, { "title": "5.1.1. Heading", "parent": "abcnoh-5-1", "id": "abcnoh-5-1-1" }, { "title": "5.2. Heading", "parent": "abcnoh-5", "id": "abcnoh-5-2" }, { "title": "4. Heading", "parent": "root", "id": "abcyesh-4" }, { "title": "4.1. Heading", "parent": "abcyesh-4", "id": "abcyesh-4-1" }, { "title": "5. Heading", "parent": "root", "id": "abcyesh-5" }, { "title": "5.1. Heading", "parent": "abcyesh-5", "id": "abcyesh-5-1" }, { "title": "5.1.1. Heading","parent": "abcyesh-5-1","id": "abcyesh-5-1-1"}, { "title": "5.2. Heading", "parent": "abcyesh-5", "id": "abcyesh-5-2" } ]Or should I make the work and try to program a possible extension on nodejs level?
-
The flow is like this:
- Your template runs in the nodejs sandbox and evaluates handlebars. There is no DOM or inline script evaluated.
- The helpers like
pdfAddPageItemare evaluated and puts to the html output some specific text-based marks. - The chrome gets HTML, and evaluates it together with inline scripts in DOM, and outputs pdf. We have only a little influence here.
- if there is a pdf utils operation like merge or append, the pdf utils parses the chrome-produced pdf, finds the hidden marks and reconstructs information added with pdfAddPageItem, this data are then passed in the
$pdfto a template that is merged or appended
You cant run helpers from inside an HTML inline script because it is a completely different context and process. While the handlebars are executed in the node, the inline script is executed in chrome.
Your main problem is being able to put the TOC anywhere in the template?
As you probably noted, the main problem are the page numbers, which we can't obtain before sending to chrome, therefore we are rendering TOC twice.
To be able to simply put TOC for example in the middle of the document, you can render the whole template twice. The first time you collect information about page numbers and then in the second render you have everything you need.
A demo
https://playground.jsreport.net/w/anon/6hbllD25
I am still evaluating some other approaches...
-
This could look pretty interesting. And I might have an interface to exchange data between the two renderings.
On the first render i run an inline script at the end of DOM, and put a pseudo handlebar at the end of body:
toc = [{items: []}] const regex = /<h([1-6]).*>(.*)<\/h\1>/g; const str = document.getElementsByTagName('body')[0].innerHTML; let m; let tocItems = [] while((m = regex.exec(str)) !== null) { if(m.index === regex.lastIndex) { regex.lastIndex++; } let div = document.createElement('div'); div.innerHTML = m[0].trim(); let header = { title: div.firstChild.innerHTML, id: div.firstChild.id, parent: div.firstChild.getAttribute('data-parent') || null, } toc[0].items.push(header) tocItems.push(header) m.forEach((match, groupIndex) => { console.log(`Found match, group ${groupIndex}: ${match}`); }); } let secondRenderJsonData = [] // PARSE STUCTURE toc.forEach((page, pIndex, arr)=> { page.items.forEach((item, iIndex, arr)=> { if(item.title) { secondRenderJsonData.push({id: item.id, title: item.title, parent: item.parent || null, page: pIndex + 1}) } }) }) var code = document.createElement('code') code.setAttribute('ref', 'toc') code.innerHTML = '{' + '{#secondRenderJsonData}}' + JSON.stringify(secondRenderJsonData) + '{' + '{/secondRenderJsonData}}' console.log('code', code.outerHTML) document.getElementsByTagName('body')[0].appendChild(code);Then i use your second rendering approach, with filtering the pseudo handlebar and pass it as parsed json data to the second rendering:
async function afterRender (req, res) { if (req.data.secondRender) { return } const $pdf = await jsreport.pdfUtils.parse(res.content, true) let page = $pdf.pages[$pdf.pages.length] let jsonData = [] for(var i=0; i <= $pdf.pages.length; i++) { let page = $pdf.pages[i] //console.log('parsedResult', page) if(page && page.text) { const regex = /{{#secondRenderJsonData}}(.*){{\/secondRenderJsonData}}/gm; let m; while ((m = regex.exec(page.text)) !== null) { if (m.index === regex.lastIndex) { regex.lastIndex++; } if(m[1]) { jsonData = m[1] } } } } //console.log('jsonData: ', jsonData); const finalR = await jsreport.render({ template: { name: 'template', }, data: { ...req.data, $pdf: $pdf, firstRenderPdf: $pdf, secondRender: true, secondRenderTOC: (typeof jsonData === 'string') ? JSON.parse(jsonData) : jsonData, } }) res.content = finalR.content }And then i write the links dynamically with the #each loop handlebar syntax:
{{#each secondRenderTOC}} <a class="block" title="{{this.title}}" href="#{{this.id}}" data-pdf-link-target-id="{{this.id}}" data-pdf-outline data-pdf-outline-title="{{this.title}}" data-pdf-outline-parent="{{this.parent}}" > <div class="relative w-full"> <span class="chapter w-full block">{{this.title}}</span> <strong class="page absolute top-0 right-0 pl-2 bg-white">{{getPageNumber this.id}}</strong> </div> </a> {{/each}}Here my fork of your solution: https://playground.jsreport.net/w/fhrtms/z9GUrD79
I'll test it again in a more complex structure.
-
Ok, I tried it and found it to be excellent.
https://playground.jsreport.net/w/fhrtms/WDA4w4ao
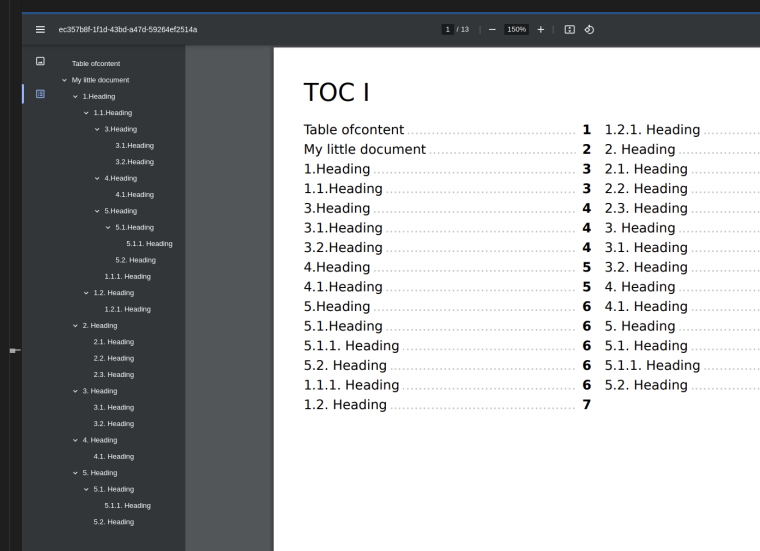
But i found a little bug with spaces:
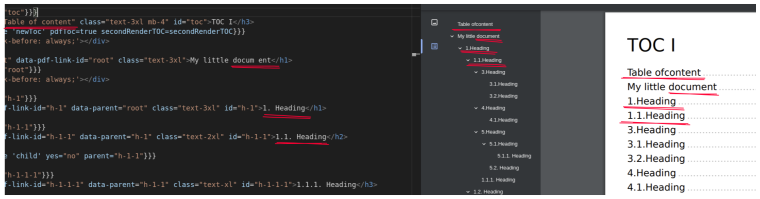
It is always the last space of innerHTML property.
-
You really don't give up easily, I like that :)
The pdfjs lib which is used to parse the pdf text has issues with spaces. We solve it here by trimming
https://github.com/jsreport/jsreport/blob/master/packages/jsreport-pdf-utils/lib/utils/parsePdf.js#L3You could do the same, base64 encode the values to avoid spaces and use similiar regexp like we use to find what you need.
However, maybe you can try the following approach using
console.log. It could make things simpler. Just note there is limit 1000 chars for single console.log.
https://playground.jsreport.net/w/anon/jciOAKws
-
Base64 is not the best solution, at least not for utf8. Some special characters are not encoded correctly.

So I just replace the spaces with the html equivalent
title.replace(/ /gi, ' ').And with a very long TOC in the attached code tag, which contains the headers as JSON code, split by a page break, the readout in the
afterRendervia regex no longer works. So I tried to minimize the font size.code.setAttribute('style', 'font-size: 0.05px;')What is the smallest font size that is rendered?
-
You can find inspiration in pdfAddPageItem
https://github.com/jsreport/jsreport/blob/master/packages/jsreport-pdf-utils/static/helpers.js#L103Base64 is not the best solution, at least not for utf8. Some special characters are not encoded correctly.
I don't see a reason why this shouldn't work. base64 can encode and decode everything, even images.
What is the smallest font size that is rendered?
See here, we use 1.1px size and opacity 0.01
const jsonStrOriginalValue = JSON.stringify(item) const value = Buffer.from(jsonStrOriginalValue).toString('base64') // we use position: absolute to make the element to not participate in flexbox layout // (making it not a flexbox child) const result = `<span class='jsreport-pdf-utils-page-item jsreport-pdf-utils-hidden-element' style='font-family: Helvetica;position:absolute;text-transform: none;opacity: 0.01;font-size:1.1px'>item@@@${value}@@@</span>`
-
But in the inline script to parse the DOM i can't use
new Buffer.from(title, 'utf8').toString('base64'). I can only useatob/btoathere.
-
With your solution i get an error
Unexpected token � in JSON at position 0...const jsonStrOriginalValue = JSON.stringify(secondRenderJsonData) const value = btoa(jsonStrOriginalValue) //unescape(encodeURIComponent()) //Buffer.from(jsonStrOriginalValue).toString('base64') document.getElementsByTagName('body')[0].innerHTML += `<span class='jsreport-pdf-utils-page-item jsreport-pdf-utils-hidden-element' style='font-family: Helvetica;position:absolute;text-transform: none;opacity: 0.01;font-size:1.1px'>item@@@${value}@@@</span>`Error when evaluating custom script /main.js Unexpected token � in JSON at position 0 (sandbox.js line 33:19) 31 | } 32 | > 33 | const $pdf = await jsreport.pdfUtils.parse(res.content, true) | ^ 34 | let page = $pdf.pages[$pdf.pages.length] 35 | let jsonData = [] 36 | SyntaxError: Unexpected token � in JSON at position 0What is the meaning of the notation
item@@@...@@@?
Is this somehow processed differently?If I use
itemm@@...@@@or something else, it works. But the base64 string (content between @@@...@@@) gets clipped when I try to get it via regex, probably it gets clipped at the page margin.
-
But in the inline script to parse the DOM i can't use new Buffer.from(title, 'utf8').toString('base64'). I can only use atob/btoa there.
Yes, true, that didn't come to my mind.
What is the meaning of the notation item@@@...@@@?
Is this somehow processed differently?Yes, this is our internal mark, which pdf utils remove during post-processing and from the information builts
$pdf.pages.itemscollection you typically use during the merge operations.I've spent some time analyzing the options we have for improving the ToC, but I didn't find some breaking ideas to make things easier for you.
I'm not sure creating ToC from DOM is the right way to go, but I at least added the official example to the documentation for rendering ToC without the previous declaration and with ToC position directly in the main template.
https://playground.jsreport.net/w/admin/tV6sVKbV
This was triggered by ideas in this thread. Thank you
