FATAL ERROR: Ineffective mark-compacts near heap limit Allocation failed - JavaScript heap out of memory
-
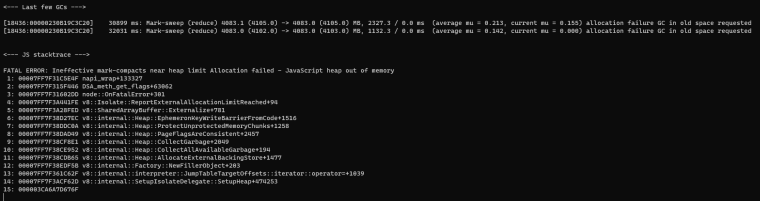
I leave here the link of my json , where you can see that I have a lot of data. And it is recurring that I have reports with this size, due to the many transactions
https://we.tl/t-LzeybgDoSwMy jsreport.config
My package

I've tried on another machine to put the latest version of jsreport but I have the same problem.
The errors that usually appear to me are Payload to large, heap out of memory
Any solution you recommend? Because I have several clients that need long reports, as in this case
-
hi! yes, it is expected that by default you get out of memory errors with such long reports, after all it is node.js default not to use all memory available.
you need to set the node.js option
--max-old-space-size, which expects a value in megabytes.depending on how you start the jsreport you need to either pass it as a node.js option or an env var
node --max-old-space-size=3000 server.jsNODE_OPTIONS=--max-old-space-size=3000 jsreport startorNODE_OPTIONS=--max-old-space-size=3000 node server.js
you will need to figure it out the exact megabytes value to pass, depending on the available memory you have on the machine, it is a bit of trial and error until you get right value for your reports.
-
also, since you are on the v2 version it is likely you need to follow other configurations like the ones described in this blog post, but the
--max-old-space-sizenode.js option is the most important
-
there is possibility to have multiple json files in a single template?
-
no, there can be only one data entity attached to the template, but of course, you can still have many of them saved and available.
the data entity is mostly for testing purposes and to verify that your template produces the expected output during your development. so it makes sense to have just one of them attached to a template on each render.
what would be the use case of having multiple of them in a single template?
-
The case would be instead of sending a json with millions of lines, "split" that json into several and send these jsons through my API (C#)
And so it would probably avoid timeout and memory errors
-
I am afraid that such approach does not solve the issue with memory, receiving the input data is just one part of the puzzle and it becomes meaningless if the rest of the tasks (handlebars rendering, chrome rendering, etc) do not work the same way, because eventually some of these tasks will require having everything in memory.
we have some ideas to make handlebars to work this way (for the output part, not the input), but as I said it depends on the rest of the tasks that are going to be done, and it does not work for all cases/recipes.
because of these points, receiving the input data this way does not represent an advantage right now. in an ideal world each task supports getting input and producing output in a streaming way but this is not possible so far.
