If anyone is interested, or encounters the same problem.
Topping out the CPU is really bad. When it reaches the top, the current report rendering seems to slow down to almost stand-still. I was contemplating setting up a second JSReport server, but that would not have solved our type of load. We have very few renderings (10-20 per day), but sometimes really big reports are rendered. The most important bottleneck in our setup seems to be topping out the CPUs.
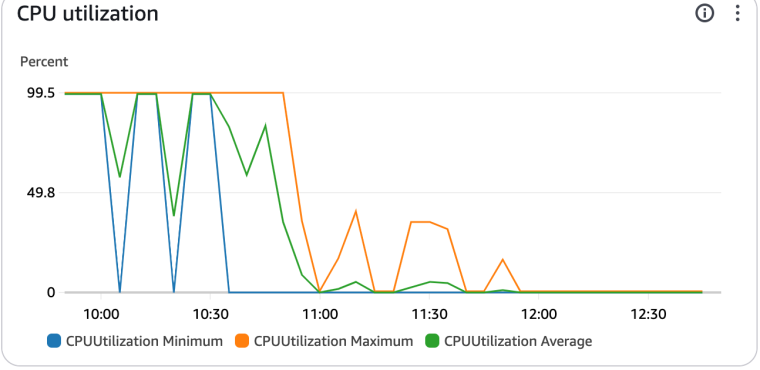
The left part of this chart shows three attempts to render a very large report. Each of the attempts timed out after 10 minutes.
To the right in the chart, the same report is rendered two times after upgrading from 2 vCPU to 4 vCPU. Each render took about 40-42 seconds.
The last cpu bump is a smaller report. This particular report was actually rendered successfully with 2 vCPUs a couple of days ago, so I had metrics to compare. With 2vCPUs the smaller report took 14 seconds to render. After the upgrade, the same report took 9 seconds. This is a reasonable performance bump, but its always nice with confirmation.