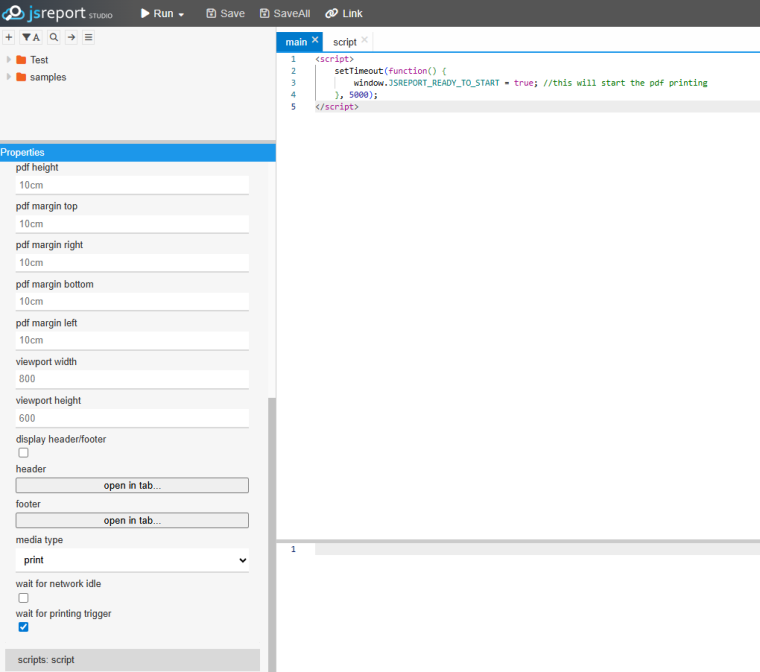
We have deployed jsreport (4.10.1) on a dedicated VM in the Production environment.
Configuration is as follows -
RAM: 32GB
CPU: 4 Cores
Architecture: x64
(non-containerised)
numberOfWorkers: 1
We keep getting Worker terminated due to reaching memory limit: JS heap out of memory once in a while. And it gets crashed and restarts after that.
Could you please let us know if we need to change any configurations or settings to avoid this issue?
Following is the error screenshot:
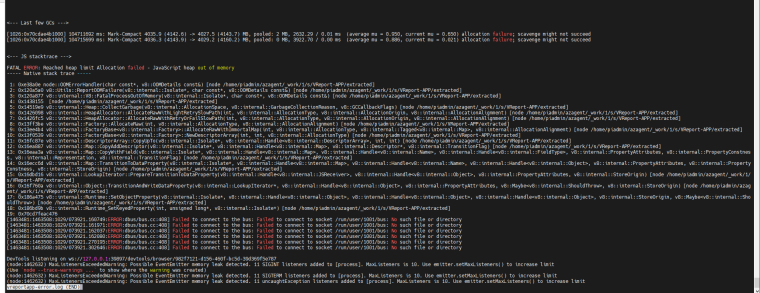
Let us know if you need any additional details.
We have some queries:
Could you please let us know the default heap size?
How many percentage of RAM should be allocated to heap?
If we have set only one worker then why are we getting heap size limit issue?
Do references held by previous renders get freed up after report rendering finishes?
Please let us know so that we will be able to monitor and set appropriate configurations.